I – Introduction au Serverless
L’informatique serverless (sans serveur) permet aux développeurs de créer des applications plus rapidement en éliminant la nécessité de gérer l’infrastructure. Avec les applications serverless, le fournisseur de services cloud fournit, met à l’échelle et gère automatiquement l’infrastructure requise pour exécuter le code.
Pour comprendre ce qu’est par définition l’informatique serverless, il est important de noter que les serveurs exécutent toujours le code. Le terme serverless vient du fait que les tâches associées au provisionnement et à la gestion de l’infrastructure sont invisibles pour le développeur. Cette approche permet aux développeurs de se concentrer davantage sur la logique métier pour répondre au besoin du client. L’informatique serverless aide les équipes à augmenter leur productivité et à commercialiser plus rapidement les produits. Elle permet également aux entreprises d’optimiser leurs ressources.
II – Introduction à Kubernetes
Kubernetes est une plateforme open source extensible et portable permettant d’automatiser le déploiement, la mise à l’échelle et la gestion des charges de travail conteneurisées. Kubernetes simplifie la complexité de la gestion des conteneurs en nous fournissant une configuration déclarative pour orchestrer les conteneurs dans différents environnements de calcul.
Les principales fonctionnalités de Kubernetes sont :
- Exécution et orchestration des conteneurs
- Automatisation des déploiements des conteneurs
- Mise à l’échelle
- Découverte des services : Vous n’avez pas besoin de mettre en place un mécanisme de découverte de services, car kubernetes attribue un nom unique et un dns aux pods
- EndPoint Slices : suivi évolutif des réseaux Endpoints dans un cluster Kubernetes.
- Gestion des secrets
III – Kubernetes vs Serverless
L’informatique Serverless a été démocratisé par les fournisseurs de plateforme Cloud (Amazon, Microsoft, etc.). Le principal avantage mis en avant est le provisionnement dynamique des ressources d’exécution de votre application, en fonction de ses besoins. Aucune ressource n’est donc provisionnée pour une application qui ne reçoit aucune requête. Ainsi, le développeur peut se concentrer uniquement sur son application, sans se soucier de l’infrastructure d’exécution.
De nos jours on serait tenté de croire que le serverless est uniquement disponible lorsqu’on utilise une plateforme Cloud. Si je suis intéressé par cette approche de provisionnement des ressources pour mes applications qui vont s’exécuter sur site, comment procéder ? Vous pouvez à ce moment vous orienter vers Kubernetes.
Kubernetes, grâce à ses fonctionnalités d’orchestration et de mise à l’échelle automatique est un bon candidat pour la mise en place d’une plateforme d’exécution des applications orientée Serverless. Mais, il souffre toutefois de quelques manquements :
1 – absence de mise à l’échelle de 0 à n et de n à 0
Une plateforme dite serverless doit être capable de provisionner les instances d’une application partant de 0 jusqu’à N. Pareille lorsque c’est le moment de procéder à la mise à l’échelle descendante.
Les fonctionnalités de mises à l’échelle de Kubernetes permettent de mettre à l’échelle partant de 1 à n et vice-versa. Donc, pour une application qui ne reçoit aucune requête pendant une longue période, il y’aura toujours au minimum une instance de cette application en cours d’exécuter dans un cluster Kubernetes. Ce qui ne répond pas aux fondamentaux du Serverless.
2 – Nombre de noeuds minimal et maximal
La fonctionnalité de mise à l’échelle automatique de Kubernetes vous oblige de définir un nombre de nœuds minimal et un nombre de nœuds maximal pour votre application.
3 – Mise à l’échelle lente
Si votre application doit rapidement se mettre à l’échelle, il est possible que certains pods restent en état d’attente de planification, jusqu’à ce que les nœuds supplémentaires déployés par l’autoscaler de cluster puissent accepter les pods planifiés.
4 – Mise à l’échelle basée sur la consommation des ressources
Les services Serverless des plateformes infonuagiques procèdent à la mise à l’échelle sur la base de plusieurs critères :
- Consommation des ressources
- Nombre de requêtes reçues
- Nombre de messages dans une file d’attente
- Etc.
Kubernetes procède à la mise à l’échelle automatique en se basant uniquement sur les métriques de consommation des ressources matérielles. De ce fait, il ne sera pas en mesure de créer, par exemple, de nouvelles instances d’une application si des messages s’accumulent dans la file d’attente parce que l’application ne peut pas les traiter aussi rapidement qu’ils arrivent.
IV – Comment faire de Kubernetes une plateforme Serverless ?
Pour pallier à ces limites, de nombreux composants ont vu le jour pour doter la plateforme des fonctionnalités permettant de répondre aux besoins mentionnés ci-haut. Les plus importants sont :
- Keda
- Knative
- Kubeless
V – Keda
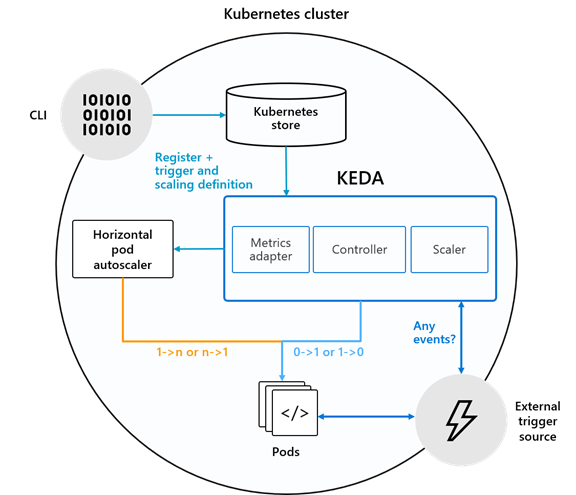
KEDA (Kubernetes-based Event Driven Autoscaler) est un outil permettant de piloter la mise à l’échelle de n’importe quel conteneur dans Kubernetes en fonction du nombre d’évènements à traiter.
KEDA est un projet initié par Microsoft, qui a été rejoint par Red Hat et une forte communauté d’éditeurs de logiciel. La plateforme est sous la gouvernance de la Cloud Native Computing Foundation.
KEDA est un composant léger et à usage unique qui peut être ajouté à n’importe quel cluster Kubernetes. KEDA fonctionne avec des composants Kubernetes standard tels que l’ autoscaler de pod horizontal (HPA) et peut étendre les fonctionnalités sans écrasement ni duplication. Avec KEDA, vous pouvez mapper explicitement les applications que vous souhaitez utiliser à l’échelle évènementielle. Cela fait de KEDA une option flexible et sure pour fonctionner avec n’importe quel nombre d’autres applications ou framework Kubernetes.
KEDA joue deux rôles clés au sein de Kubernetes:
- Agent – KEDA active et désactive les déploiements Kubernetes pour évoluer vers et à partir de zéro sur aucun évènement. C’est l’un des rôles principaux du keda-operatorconteneur qui s’exécute lorsque vous installez KEDA.
- Métriques – KEDA agit comme un serveur de métriques Kubernetes qui expose des données d’évènement riches telles que la longueur de la file d’attente ou le décalage du flux à l’autoscaler de pod horizontal pour réduire la montée en puissance
Dans les coulisses, KEDA agit pour surveiller la source de l’évènement et alimenter ces données vers Kubernetes et le HPA pour accélérer la mise à l’échelle d’une ressource. Chaque réplica d’une ressource extrait activement des éléments de la source d’évènement.
Par exemple, si vous vouliez utiliser KEDA avec une rubrique Apache Kafka comme source d’évènement, le flux d’informations serait:
- Lorsqu’aucun message n’est en attente de traitement, KEDA peut mettre à l’échelle le déploiement à zéro.
- Lorsqu’un message arrive, KEDA détecte cet évènement et active le déploiement.
- Lorsque le déploiement commence à s’exécuter, l’un des conteneurs se connecte à Kafka et commence à extraire les messages.
- Au fur et à mesure que de plus en plus de messages arrivent sur le sujet Kafka, KEDA peut transmettre ces données à la HPA pour accélérer la montée en puissance.
- Chaque réplica du déploiement traite activement les messages. Très probablement, chaque réplica traite un lot de messages de manière distribuée.
KEDA supporte plus d’une cinquantaine de sources.

VI – Knative
Knative est une plateforme serverless Kubernetes créée par Google avec la contribution de plusieurs entreprises. Knative offre un ensemble essentiel de composants pour créer et exécuter des applications sans serveur sur Kubernetes.
Knative offre des fonctionnalités telles que le scaling à zéro instance, l’autoscaling, les compilations en cluster et le framework d’évènements pour les applications cloud natives sur Kubernetes. Que ce soit sur site, dans le cloud ou dans un centre de données tiers, Knative codifie les bonnes pratiques partagées par des frameworks existants basés sur Kubernetes et qui ont fait leurs preuves. En outre, Knative permet aux développeurs de se concentrer sur l’écriture du code plutôt que de gérer les aspects fastidieux de la création, du déploiement et de la gestion d’une application.
Knative supporte plusieurs langages et Framework dont C#, Go, Java (Spark), Java (Spring), Kotlin, Node.js, PHP, Python, Ruby.
Knative est conçu pour s’intégrer facilement à des builds et à des chaînes d’outils CI/CD existants. En se concentrant sur des technologies Open Source qui s’exécutent partout, sur n’importe quel cloud et sur toutes les infrastructures compatibles avec Kubernetes.
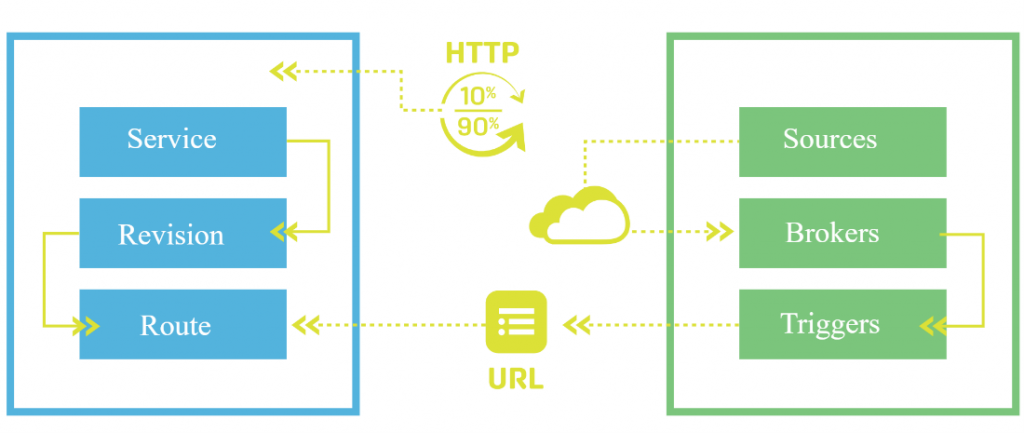
Knative est architecturé autour de deux composants majeurs : Servicing et Eventing
- Le Serving contient les outils et services nécessaires pour exécuter du Serverless sur Kubernetes avec simplicité. Il s’agit entre autres de la réseautique, de la mise à l’échelle automatique, du suivi des révisions, etc.
- Eventing : ce composant permet de se connecter à des sources d’évènements externes pour effectuer la mise à l’échelle. De nombreuses sources d’évènement sont supportées dont : Apache Kafka, Apache Camel, GitHub, RabbitMQ, Amazon DynamoDB, Amazon S3, Azure Service Bus, Azure Event Grid, Azure Event Hubs Azure Blob Storage, etc.
Site du projet : https://knative.dev/docs/
VII – Kubeless
Kubeless est un framework serverless Kubernetes. Il est développé en open source et est maintenu par VMware.
Kubeless vous permet de déployer sur Kubernetes des petits bouts de code (fonctions) sans vous soucier de la plateforme d’exécution. Il offre au travers de Kubernetes des fonctionnalités de mise à l’échelle automatique, le routage d’API, la supervision, le dépannage, etc.
Kubeless supporte de nombreux langages, dont Node.js, Python, Ruby, etc.
Le projet à date ne bénéficie plus du support de VMware. Son dépôt sur GitHub est archivé. Donc je vous recommande de vous tourner vers d’autres solutions comme KEDA et Knactive.
Site du projet : https://github.com/vmware-archive/kubeless
VIII – Conclusion
Grâce à ces outils, vous êtes capable de doter de Kubernetes des fonctionnalités d’une plateforme d’exécution d’applications serverless. Maintenant, il ne vous reste plus qu’à implémenter vos applications, en tenant compte, toutefois, du fait qu’elle doit respecter l’architecture serverless.